by Dave Crader
Ever had your content stolen? It recently happened to us and we certainly did not appreciate it. We spend hours writing well-researched original articles because that’s what our readers deserve. You won’t find any rewriting here. The downside to this, as we recently discovered, is becoming a target for copyright infringement. Luckily, we were able to get the copied content removed in this case, but I doubt it will always be so easy. In this post we’ll go over a few options you have if this ever happens to you, and we’ll help you identify duplicate content on your own site that you may not even know existed.
There are a lot of misconceptions about Google’s duplicate content penalty, so let me explain the basics before we dive in.
Duplicate Content Off-Site
A lot of duplicate content is created by scraper websites known as ‘autoblogs.’ Autoblogs are set-up by low-life scumbags who don’t have the creative skill to write their own material. These autoblogs are configured to scrape your website and steal your content almost instantly after you’ve posted it. This confuses search engine spiders because they don’t know which site is the source of the original content. If the spiders crawl the autoblog before crawling your website they will think the autoblog is the original source and you are the copier. If the spiders crawl your content before crawling the autoblog, you should be safe from penalties. It’s not as clean cut as that, but that’s the general idea. Either way, it’s worth your time to proactively pursue content thieves just to be safe.
1. Contact the Site Owner and Ask for Removal
I was doing some research for our new mobile app service page and stumbled across an article that looked strikingly similar to David’s stellar mobile website blog post from back in June. I ran David’s article through copyscape.com, a free online plagiarism checker, and was surprised to find not just one infringer, but two. I immediately sent a friendly yet direct e-mail to the website owners in hopes of getting the copied content removed.

This is one of the e-mails I received back:

I won’t expose this individual since he complied, but it’s interesting that he didn’t know about basic copyright infringement laws. When a tangible idea is shared with at least one other person it becomes protected under U.S. copyright law. A tangible idea can be defined as any idea that is spoken or written. It really does not matter if ‘Copyright ©’ appears next to the idea or not. ‘Copyright ©’ is just a way to warn people that the idea is protected. Like any law, there are various odd exceptions that come into play, but I’ll leave those to the U.S. Copyright Office to explain. The other infringing website owner did not respond to my e-mail, but the page was also removed promptly.
2. Contact the Site’s Host and Ask for Removal
I’ve never had to go straight to the hosting provider, but Google recommends it on its duplicate content help page. I didn’t know hosting providers were required to accommodate such requests, but if they are, it seems like this would be a very effective method.
3. File Lawsuit
You can always have your lawyers write up an official cease and desist letter if you’d like, but this is usually pretty expensive. I’d go with option one or two before heading down this path.
If you can’t get a hold of anyone you can always file a request for Google to remove the infringing page from its search results. The copied content will remain, but no one will be able to find it in search results. This will also remove the risk of any duplicate content penalties Google may have assigned to your website.
Duplicate Content On-Site
On-site duplicate content is very common. It’s arguably more dangerous than off-site duplication because precious link juice is being spread thin in multiple directions. Off-site duplication doesn’t split link juice, it just tells search engines not to give any juice to the copied version.
Canonicalization Issues
For example, let’s take a look at Gojo.com. Gojo’s® homepage is splitting link juice in 6 directions causing canonicalization issues. We know this because each of the following URLs displays the exact same homepage content.
• http://gojo.com/
• http://www.gojo.com/default.asp
• http://www.gojo.com/default.aspx
• http://gojo.com/default.aspx
• http://gojo.com/default.asp
• http://www.gojo.com/
Google gets confused by this because it doesn’t know which URL is the primary version that Gojo would like to rank in search. If Google doesn’t know which version is the primary, it makes a guess based on backlinks and other factors.
The split has also caused a link equity problem. For example,
http://gojo.com/ - has 20 backlinks.
www.gojo.com - has 891 backlinks.
Google assumes www.gojo.com is the primary version because of the backlinks, but that doesn’t necessarily fix the problem. The company is still missing out on some precious link juice from the 20 people who linked to http://gojo.com instead of www.gojo.com. All of these problems can be easily fixed with a 301 redirect or a rel=”canonical” attribute specifying one primary version of the URL.
A rel=”canonical” attribute will only redirect search engine spiders, not users.
A 301 redirect will redirect both search engine spiders and users.
Duplicate Title Tags
Looking at the Title tags of a website is an easy way to detect duplicate content issues. You can find duplicate title tags in the Diagnostic section of Google webmaster tools. If you don’t have Google Webmaster Tools set up you can use Xenu Link Sleuth instead (Mac users will need to use Screaming Frog).
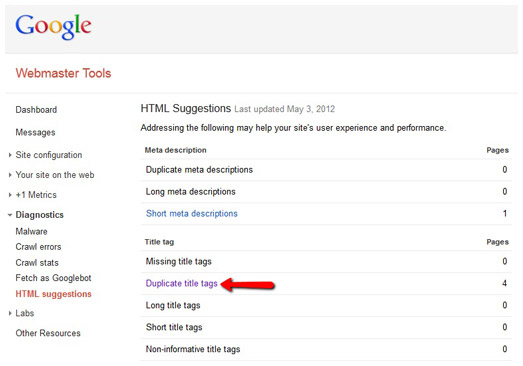
Two pages that have the same title tag often have the same content as well. To fix this, you should apply a 301 or rel=”canonical” attribute to specify a primary version. If one page has accrued more backlinks than the other, I’d recommend choosing the page with backlinks as the primary.
Duplicate "Print Friendly View" Pages
A lot of webmasters offer visitors a ‘print friendly view’ of their website’s pages. This is great for users, but bad for search engines because two pages with the exact same content will exist on the website. The rel=”canonical” attribute can be used in this situation because it will eliminate the duplicate content issue while still allowing users to access the print friendly page. If a 301 is used the user would be redirected back to the same page that he/she is currently on. The rel=”canonical” attribute was actually invented for this very reason. Here at Evolve, we avoid this issue completely by using print friendly style sheets and CSS. These style sheets use a different set of css properties for when a browser attempts to print a page. This creates a print friendly version of the page without needing a separate URL. Smashing Magazine has a great tutorial for accomplishing this.
Search engines hate duplicate content because they don’t know which version to show in search results. They’re already dealing with over a trillion web pages - why make their job even harder? If you think you may have some duplicate content issues, just give us a call at 234-571-1943 for some help.